This is a guest post by Aakash Pradeep, Principal Software Engineer, and Venkatram Bondugula, Software Engineer at Twilio, in partnership with AWS.
Twilio is a cloud communications platform that provides programmable APIs and tools for developers to easily integrate voice, messaging, email, video, and other communication features into their applications and customer engagement workflows.
In this blog series we discuss how we built a multi-engine query platform at Twilio. The first part introduces the use case that led us to build a new platform and why we selected Amazon Athena alongside our open-source Presto implementation. This second part discusses how Twilio’s query infrastructure platform integrates with AWS Lake Formation to provide fine-grained access control to all their data.
At Twilio, we faced critical challenges in managing our multi-engine query platform across a complex data mesh architecture spanning multiple AWS accounts and Lines of Business. We needed a unified permissions model that could work consistently across different query engines like OSS Presto and Amazon Athena, eliminating the fragmented authentication experiences in our infrastructure. The growing demand for secure cross-account data sharing required moving beyond manual, multi-step provisioning processes that depended heavily on human intervention. Additionally, Twilio’s compliance and data stewardship requirements demanded fine-grained access controls at row, column, and cell levels, necessitating a scalable and flexible approach to permission management. By adopting the AWS Glue Data Catalog as our managed metastore and AWS Lake Formation for governance, we implemented Tag-Based Access Control (LF-TBAC) to simplify access management, enabled data sharing through automated workflows, and established a centralized governance framework that provided uniform permissions management across all AWS services.
We discussed in part 1, how we were looking to move to managed services to alleviate us of the burden of managing the underlying infrastructure of a query platform. Along with our decision to adopt Amazon Athena, we also began to evaluate the adoption of Amazon EMR Serverless for our Spark workloads, which made us aware of the fact that we needed to migrate to a managed solution for our Apache Hive metastore.
We selected the AWS Glue Data Catalog as our managed metastore repository to support our enterprise-wide data mesh architecture. For managing permissions to the Data Catalog assets, we chose AWS Lake Formation, a service that enables data governance and security at scale using familiar database-like permissions. Lake Formation provides a unified permissions model as well as support for enabling data mesh architecture that we were seeking.
Lake Formation’s support for row, column, and cell-level access controls provides the fine-grained access control (FGAC) capabilities required by our compliance and data stewardship policies. Additionally, Lake Formation’s tag-based access control (LF-TBAC) feature allows us to define FGAC permissions based on tags attached to the Data Catalog resources, enabling flexible and scalable permission management.
Odin, our Presto-based gateway, serves as a central hub for query processing, managing authentication, routing, and the complete workflow throughout a query’s lifecycle. As the primary interface, Odin enables users to connect through JDBC or APIs from various BI tools, SQL IDEs, and other applications.
Beyond its core routing capabilities, Odin utilizes local caches implemented using Google’s Guava caching library to optimize performance across the platform. Guava delivers efficient in-memory caching for Java applications by storing data locally within the application instance, resulting in significantly faster retrieval times. Odin employs multiple Guava caching layers across various modules to ensure optimal response times for frequently accessed data and metadata.
Building on this performance foundation, Odin implements authentication and authorization layers to ensure secure and controlled access to data across multiple query engines. These security components work together to verify user identities and enforce data access policies, providing a unified security framework that abstracts away the complexities of individual engine implementations while maintaining strict governance standards.
Different query engines like OSS Presto and Amazon Athena each implement their own authentication mechanisms. To create a consistent user experience, Odin provides a unified authentication layer that shields users from these underlying differences. Currently, Odin’s pluggable authentication system supports LDAP integration, with plans to expand this capability to include Okta authentication using IAM Identity center in the future.
For data consumers using AWS Analytics services such as AWS Glue, Amazon EMR, and Athena through an IAM federated role-based access, AWS Lake Formation provided critical authorization capabilities for data governance through their existing integrations. However, we needed to extend its capabilities to integrate with OSS Presto. Additionally, our users for the query infrastructure platform were not mapped to an IAM user so would need to build a custom authorization layer in Odin to verify permissions and integrate with Lake Formation. Our challenge was creating a consistent way to control data access across all our query engines.
When a user runs a query, Odin’s authorization layer checks three key pieces of information:
We store user permissions in Amazon DynamoDB, which allows us to quickly look up what each user can access. By matching the user’s tags with the table’s Lake Formation tags, we can determine if the query should be allowed. To keep things fast, we cache this information temporarily, allowing us to expedite authorization for recent requests.
How the authorization works:
This approach allows us to make use of Lake Formation tag-based access control while keeping our authorization logic separate from the individual query engines. By using smart caching and efficient lookups, we can verify permissions in just milliseconds.
At Twilio, we have multiple line of business (LoBs) each managing their own data platform infrastructure. The individual platforms are spread across multiple AWS accounts, and primarily store data on Amazon S3 in variety of open table formats, such as Apache Hudi, Apache Iceberg, and Delta Lake. Each platform independently supports analytics and machine learning use cases, however, there was a growing need for secure sharing of data across LoBs. Additionally, we needed to enable self-service discovery and provisioning of access to the data with a centralized governance framework.
Data consumers bring their own AWS accounts and choice of tools, which include not only AWS services such as Amazon Athena, AWS Glue ETL jobs (Spark), and Amazon EMR, but also AWS partner solutions. To improve the process of access fulfillment, data auditability and lowering the operational overhead involved, we needed an automated framework in place that had minimal human intervention and oversight.
Previously, consumers requiring access to specific data sets would need to go through multiple steps to secure access, which involved several dependencies and manual actions. To simplify this process and provide a self-service capability, we decided to build a custom integration solution between ServiceNow and AWS Lake Formation. At Twilio, ServiceNow is used extensively to automate workflows and build custom applications to connect disparate systems and improve operational efficiency.
We automated key parts of the data access process using Twilio’s standard tools: Git for version control, Terraform for infrastructure management, and custom scripts to execute the necessary AWS actions.
We automated three main use cases:
1. Sharing data between accounts
When one team needs to share data with another team or with our central governance account, the process starts with a Git pull request (PR). This triggers our custom Lake Formation automation tool, which:
2. Granting permissions to user roles
When users request access to data, our automation tool grants tag-based permissions directly to their IAM roles in Lake Formation. This happens after approval of either a Git PR or ServiceNow ticket.
3. Granting access to individual users
For individual user access requests:
The overall subscription and authorization flow is as shown in the diagram below:
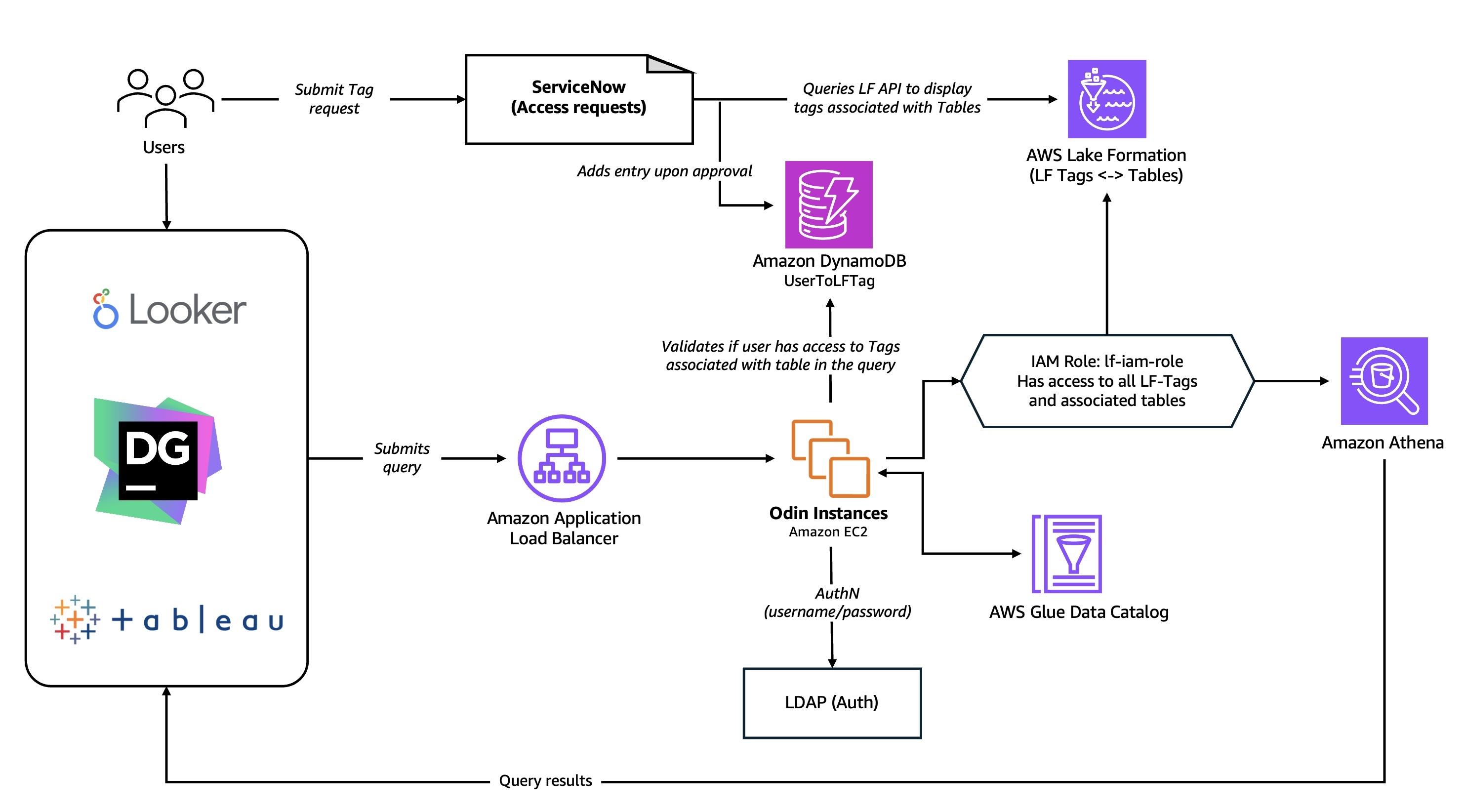
Using standardized tools and processes to provide self-service capabilities to the users helped us scale the governance framework and support broader use cases. Important capabilities in Lake Formation, such as Tag-based access control (TBAC) and cross-account sharing of data, simplified developing automations and our overall approach to governance.
“By adopting AWS Glue Data Catalog as our managed metastore and AWS Lake Formation for Tag-Based Access Control, we simplified access management and enabled data sharing by reducing auth overhead to just 6-10 milliseconds through caching and targeted scaling.”
As Odin began handling queries at scale, we encountered performance bottlenecks in our customized authorization process as we had to retrieve information from multiple services, particularly with complex queries spanning multiple tables. The authorization checks involved in the performance bottleneck frequently caused query timeouts which impacted overall system reliability. The root of the problem lay in our sequential authorization workflow: our system first had to parse each query to identify all tables requiring identity verification, then make separate API calls to the AWS Glue Data Catalog and Lake Formation for each table’s permissions. It became clear that we needed to optimize this authentication process to reduce response times and improve the overall query experience.
We also recognized there were different caching needs between our POST operations and GET/DELETE HTTP calls, so we decided to separate them into two different Application Load Balancer (ALB) target groups. For POST requests, which required Lake Formation authentication, we found that concentrating traffic through just 2-3 target instances distributed across multiple Availability Zones (AZ) was more efficient. This approach allowed authentication information to be effectively cached locally on these dedicated instances, dramatically reducing the volume of API calls to the Lake Formation service.
GET and DELETE requests follow a more simplified workflow. Since users have already completed initial authorization, there is no need to continue to perform authorization checks. Although they follow a simpler workflow, these requests have much higher volume with requests numbering into the 10s of millions per hour. Due to this scale, we opted to implement horizontal scaling to scale the target ALB to 10 Amazon EC2 instances to fetch the query history from the DynamoDB table. These EC2 instances make use of local LRU caching with a 5-minute expiration policy for authentication data.
By implementing authentication caching and adopting specialized approaches for different HTTP request types with targeted scaling groups, we successfully reduced Odin’s overall overhead to a maximum of 6-10 milliseconds for both authentication and authorization.
In this post, we explored how we enhanced Odin, our unified multi-engine query platform, with authentication and authorization capabilities using AWS Lake Formation and a custom authorization workflow. By using AWS services including Lake Formation, AWS Glue Data Catalog, and Amazon DynamoDB alongside Twilio’s existing infrastructure, we created a scalable self-service governance framework that streamlines user access management, simplifies auditing, and enables seamless data sharing across our complex cloud environment. With this workflow automation, we eliminated operational overhead while building a secure, robust platform that serves as the foundation for Twilio’s data mesh architecture.
Going forward, we are focusing on strengthening our authentication and authorization framework by enabling trusted federation with an identity provider(IdP) through AWS IAM Identity Center, which integrates directly with Lake Formation. Using Trusted Identity Propagation capabilities supported by IAM IDC will allow us to establish a consistent governance flow based on a user identity and will allow us to unlock the full capabilities of AWS Lake Formation such as fine-grained access control with data filters.
To learn more and get started with building with AWS Lake Formation, see Getting started with Lake Formation, and How to build a data mesh architecture at scale using AWS Lake Formation tag-based access control.
Aakash is a Principal Software Engineer with over 15 years of experience across ingestion, compute, storage, and query platforms. Aakash is a PrestoCon speaker, holds multiple patents in real-time analytics, and is passionate about building high-performance distributed systems.
Venkatram is a seasoned backend engineer with over a decade of experience specializing in the design and development of scalable data platforms for big data and distributed systems. With a strong background in backend architecture and data engineering, he has built and optimized high-performance systems that power data-driven decision-making at scale.
Aneesh is a Principal Analytics Solutions Architect at AWS working with Strategic customers. He is passionate about using technology advancements to solve customers’ data challenges. He uses his strong expertise on analytics, distributed systems and open source frameworks to be a trusted technical advisor for AWS customers.
Amber is a Senior Analytics Specialist Solutions Architect at AWS specializing in big data and distributed systems. She helps customers optimize workloads in the AWS data ecosystem to achieve a scalable, performant, and cost-effective architecture. Aside from technology, she is passionate about exploring the many places and cultures this world has to offer, reading novels, and building terrariums.







